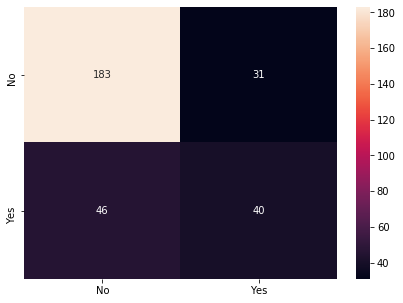
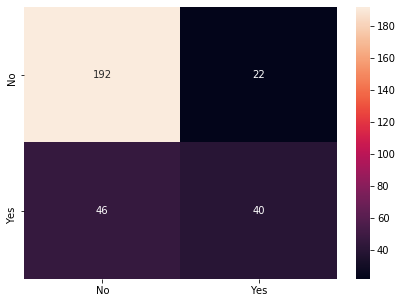
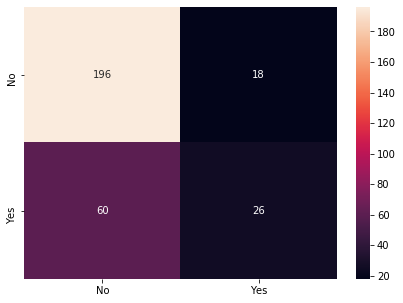
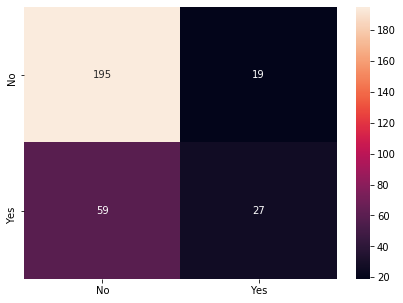
Business Problem
Build a machine learning model that predicts if someone might be a defaulter or a non-defaulter.
Data
source:
https://archive.ics.uci.edu/ml/datasets/statlog+(german+credit+data)
|
Abstract: This dataset classifies people described by a set of
attributes as good or bad credit risks. Comes in two formats (one all numeric). Also comes
with a cost matrix
|
|
|
Data Set Characteristics:
|
Multivariate
|
Number of Instances:
|
1000
|
Area:
|
Financial
|
|
Attribute Characteristics:
|
Categorical, Integer
|
Number of Attributes:
|
20
|
Date Donated
|
1994-11-17
|
|
Associated Tasks:
|
Classification
|
Missing Values?
|
N/A
|
Number of Web Hits:
|
677271
|
Independant variables
- checking_balance
- months_loan_duration
- credit_history
- purpose
- existing_loans_count
- phone
Independant variables
- amount
- savings_balance
- employment_duration
- percent_of_income
- job
Independant variables
- years_at_residence
- age
- other_credit
- housing
- dependents
Data Science Libreries
- pandas
- numpy
- sklearn
- matplotlib
- seaborn
Data Science Concepts
- Exploratory Data Analysis
- Regularization/Reducing Over fitting
- Bagging & Boosting
- Random Forest Classifier
- Decision Tree Classifier
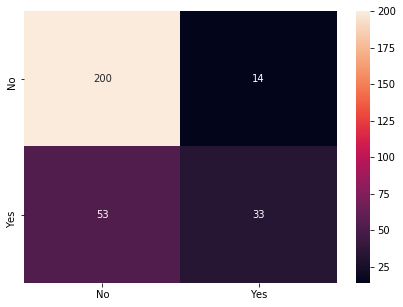
What I did
|